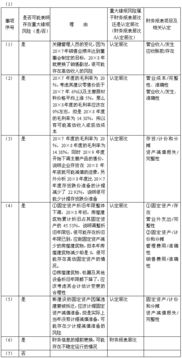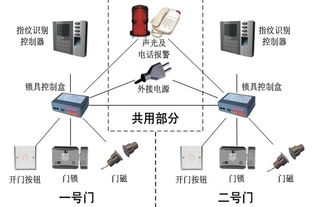
在制造業(yè)中,工廠生產(chǎn)小工單管理系統(tǒng)是提升生產(chǎn)效率和管理透明度的關(guān)鍵工具。這種系統(tǒng)主要用于跟蹤和管理生產(chǎn)現(xiàn)場(chǎng)的工單執(zhí)行情況,包括任務(wù)分配、進(jìn)度監(jiān)控、資源調(diào)度和質(zhì)量控制。常見的小工單管理系統(tǒng)包括MES(制造執(zhí)行系統(tǒng))、ERP(企業(yè)資源計(jì)劃)模塊中的生產(chǎn)管理功能,以及專門的小工單軟件,如Prodsmart、Odoo生產(chǎn)模塊等。這些系統(tǒng)通過(guò)數(shù)字化工單流程,幫助工廠減少紙質(zhì)文檔、優(yōu)化生產(chǎn)周期和降低錯(cuò)誤率。
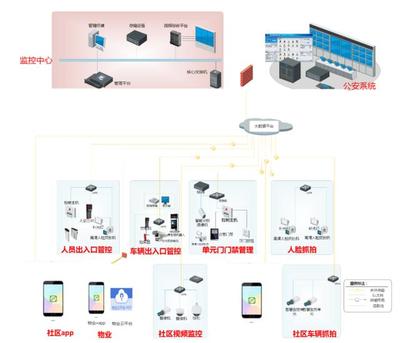
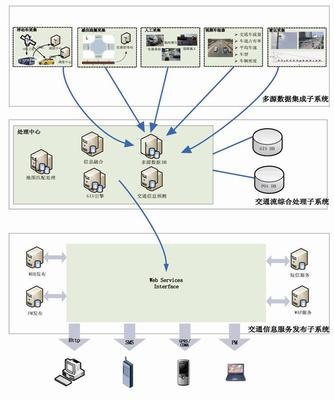
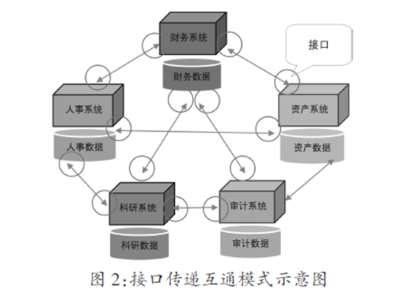
信息系統(tǒng)集成是小工單管理系統(tǒng)發(fā)揮最大價(jià)值的重要環(huán)節(jié)。集成涉及將小工單系統(tǒng)與其他企業(yè)信息系統(tǒng)連接,實(shí)現(xiàn)數(shù)據(jù)共享和流程協(xié)同。主要集成的系統(tǒng)包括:
- ERP系統(tǒng):如SAP或Oracle ERP,集成后可同步物料需求、成本核算和生產(chǎn)計(jì)劃,確保工單與整體業(yè)務(wù)目標(biāo)一致。
- MES系統(tǒng):如果小工單系統(tǒng)獨(dú)立于MES,集成后可實(shí)時(shí)采集生產(chǎn)數(shù)據(jù),監(jiān)控設(shè)備狀態(tài)和員工績(jī)效。
- 質(zhì)量管理系統(tǒng)(QMS):集成質(zhì)量檢查流程,自動(dòng)觸發(fā)質(zhì)檢工單并記錄缺陷數(shù)據(jù)。
- 設(shè)備維護(hù)系統(tǒng)(CMMS):連接后可在工單中安排預(yù)防性維護(hù),減少設(shè)備故障對(duì)生產(chǎn)的影響。
- 倉(cāng)儲(chǔ)管理系統(tǒng)(WMS):集成物料庫(kù)存信息,確保工單所需原材料及時(shí)供應(yīng)。
- IoT和傳感器系統(tǒng):通過(guò)物聯(lián)網(wǎng)設(shè)備收集實(shí)時(shí)生產(chǎn)數(shù)據(jù),用于工單優(yōu)化和預(yù)測(cè)分析。
- 商業(yè)智能(BI)工具:集成數(shù)據(jù)后生成報(bào)表,幫助管理層分析生產(chǎn)效率和瓶頸。
集成方式通常采用API接口、中間件或云平臺(tái),確保數(shù)據(jù)一致性和實(shí)時(shí)性。例如,通過(guò)RESTful API將小工單系統(tǒng)與ERP連接,實(shí)現(xiàn)工單狀態(tài)自動(dòng)更新。益處包括提高數(shù)據(jù)準(zhǔn)確性、減少人工輸入、加速?zèng)Q策速度,并支持智能制造轉(zhuǎn)型。集成也面臨挑戰(zhàn),如系統(tǒng)兼容性、數(shù)據(jù)安全和實(shí)施成本,工廠需根據(jù)自身需求選擇合適方案。小工單管理系統(tǒng)與信息系統(tǒng)的深度集成是現(xiàn)代工廠實(shí)現(xiàn)數(shù)字化和高效運(yùn)營(yíng)的核心策略。