在物聯網技術蓬勃發展的今天,數字社區的建設已成為提升城市治理現代化水平和居民生活品質的關鍵路徑。一個真正智慧、高效、人性化的數字社區,其核心并非孤立的技術堆砌,而是依賴于一個高度協同、開放共享、安全可靠的信息系統集成體系。本文將探討在物聯網時代背景下,如何通過有效的系統集成來構建面向未來的數字社區。
一、 數字社區的系統構成與集成挑戰
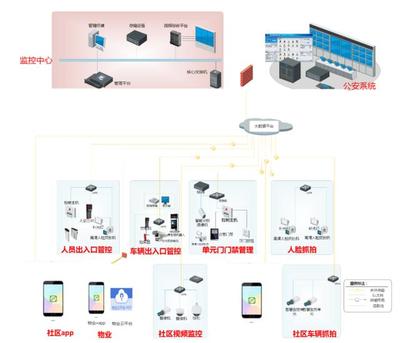
一個典型的物聯網數字社區,其信息系統通常由以下幾個層面構成:
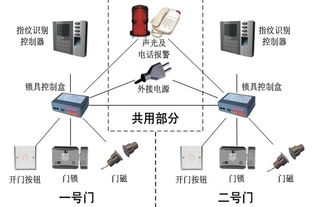
- 感知層: 遍布社區的各種物聯網終端設備,如智能門禁、環境傳感器(溫濕度、PM2.5)、安防攝像頭、智能水電表、消防感知設備、智能停車地鎖等。它們是社區的數字“感官”。
- 網絡層: 負責數據傳輸的通信網絡,包括有線寬帶、5G、Wi-Fi、LoRa、NB-IoT等,構成社區的“神經網絡”。
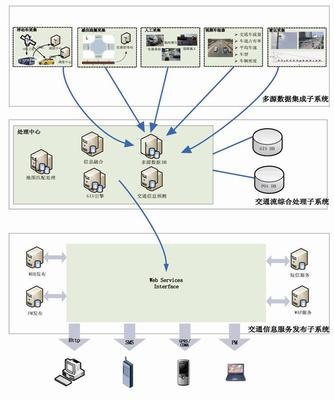
- 平臺層: 這是集成的核心,通常包括物聯網管理平臺、數據中臺、業務中臺等。它負責設備接入與管理、數據匯聚與處理、能力抽象與開放。
- 應用層: 面向不同用戶(居民、物業、政府管理部門)的具體服務應用,如智慧安防、便捷通行、智能家居聯動、社區政務、智慧養老、能源管理等。
面臨的集成挑戰主要體現在:設備協議與標準不統一導致“信息孤島”;海量異構數據難以融合與價值挖掘;各子系統(安防、停車、能源等)獨立建設,業務無法協同;以及隨之而來的數據安全與隱私保護風險。
二、 以信息系統集成為核心的構建路徑
構建數字社區,必須摒棄“煙囪式”建設模式,轉向以集成為主導的一體化設計。
- 統一規劃與標準先行: 在建設初期,就應制定社區物聯數據標準、接口規范和安全體系。優先采用或兼容主流的物聯網通信協議(如MQTT、CoAP)和數據模型,為后續集成掃清技術障礙。
- 構建融合開放的社區數字底座(平臺層集成): 這是集成的“心臟”。需要建設一個強大的社區物聯網平臺或數字中臺,其關鍵能力包括:
- 設備統一接入與管理: 通過協議適配、邊緣計算網關等方式,將不同廠商、不同類型的設備統一接入,實現集中監控、遠程運維和固件升級。
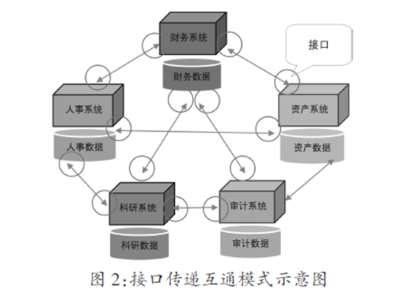
- 數據匯聚與治理: 建立社區數據資源池,對來自各子系統的結構化、非結構化數據進行清洗、關聯、融合,形成標準統一的社區數據資產。例如,將門禁通行記錄、視頻監控流、停車數據與居民身份信息進行安全脫敏后的關聯分析。
- 能力服務化封裝與開放: 將通用的能力(如人臉識別、車輛識別、報警聯動、消息推送)封裝成標準的API或微服務,供上層各類應用靈活調用,避免重復開發,促進應用創新。
- 業務聯動與場景化集成(應用層集成): 基于統一的數字底座,打破子系統壁壘,實現跨業務的智能場景。例如:
- 安全與應急聯動: 煙感報警時,不僅消防系統啟動,平臺可自動調取報警點周邊視頻、打開應急通道門禁、通知物業和業主、甚至聯動電梯迫降至首層。
- 便捷生活場景: 業主車輛進入社區時,道閘自動識別放行,并引導至空閑車位;家中空調可提前啟動調節室溫。
- 社區治理協同: 將社區安防數據、人口數據與基層治理平臺對接,為網格化管理、群租房治理、特殊人群關懷提供數據支持。
- 強化安全集成與隱私保護: 安全必須貫穿集成全過程。需建立涵蓋終端安全、傳輸安全、平臺安全和數據安全的多維防護體系。實施嚴格的權限管理、數據加密、脫敏處理和操作審計。特別是在涉及居民個人信息和生物特征數據時,必須遵循“最小必要”原則,并依法獲得授權。
三、 關鍵成功要素
- 以服務與需求為導向: 技術是手段,而非目的。集成設計應始終圍繞提升居民體驗、優化物業管理和賦能社區治理的實際需求展開。
- 建立可持續的運營模式: 數字社區的長期活力依賴于持續的運營和服務。需要明確運營主體,建立涵蓋設備維護、數據更新、應用迭代、用戶服務的常態化運營機制。
- 促進生態合作: 數字社區涉及多領域技術和服務商。構建者(通常是物業或開發商)應作為集成商和運營者,整合硬件供應商、軟件開發商、云服務商、內容服務商等,共建開放共贏的社區數字生態。
物聯網時代的數字社區,本質是一個通過深度信息系統集成而誕生的“有機生命體”。感知層如同感官,網絡層如同神經,平臺層如同大腦,應用層如同具體行為。唯有通過頂層的集成設計,打通數據血脈,聯通業務關節,才能讓這個生命體真正“智慧”起來,對外部環境做出靈敏、精準、協同的反應,最終為社區居民創造安全、便捷、溫馨、高效的現代化居住環境。構建這樣的社區,是一次從技術融合到業務重構、再到治理模式創新的系統工程。