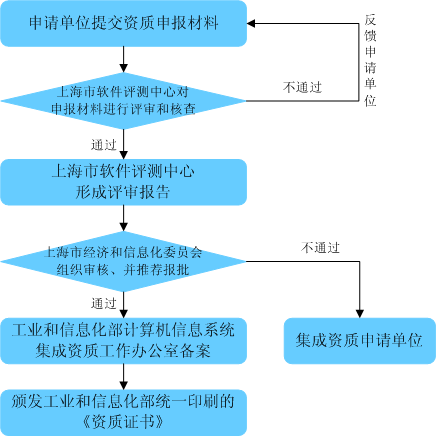
在軟件開發過程中,程序員經常需要為應用程序設置圖標。這些圖標不僅是用戶界面的視覺元素,還承載著品牌識別和功能指引的作用。不當的圖標設置可能導致資源沖突、性能下降或用戶體驗不佳。因此,圖標隔離成為開發中不可忽視的一環。
圖標隔離的核心在于確保圖標資源在應用中的獨立性、可維護性和兼容性。開發者應將圖標資源存放在專門的目錄中,如 'assets/icons',避免與其他文件混合。這有助于團隊協作時快速定位和管理圖標。使用命名規范,例如為不同分辨率或主題的圖標添加后綴(如 'iconhome24dp.png' 或 'iconhomedark.png'),可以防止命名沖突,并簡化多設備適配。
在代碼層面,圖標隔離可以通過資源管理和模塊化實現。例如,在Android開發中,利用 'res' 目錄下的 'drawable' 文件夾來組織圖標,并根據屏幕密度分類(如 'drawable-hdpi'、'drawable-xhdpi')。在Web開發中,使用CSS Sprites 或 SVG 圖標庫(如 Font Awesome)可以減少HTTP請求,同時通過類名隔離圖標樣式。現代前端框架如React或Vue允許將圖標封裝為獨立組件,通過props控制顯示,從而提升可復用性。
隔離圖標還能優化應用性能。例如,避免在運行時動態加載大量圖標,而是提前壓縮和緩存資源。同時,考慮可訪問性,為圖標添加alt文本或ARIA標簽,確保屏幕閱讀器能正確識別。
圖標隔離是軟件開發中的最佳實踐,它不僅能提高代碼質量,還能增強用戶體驗。開發者應結合項目需求,采用合適的工具和策略,確保圖標資源高效、安全地集成到應用中。